Let's Build a Local RAG System with Ollama & Qdrant - YouTube (live stream recorded)
by Maximilian Schwarzmüller Extended - YouTube
2h

Run DeepSeek-R1, Qwen 3, Llama 3.3, Qwen 2.5‑VL, Gemma 3, and other models, locally.
to run Ollama in Docker (desktop)
Basic CPU-Only Setup
- docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
-d: Runs the container in detached mode (background).-v ollama:/root/.ollama: Creates a volume to persist Ollama data.-p 11434:11434: Maps the container's port 11434 to the host's port 11434.--name ollama: Assigns the name "ollama" to the container.ollama/ollama: Specifies the official Ollama Docker image.--gpus=all: Enables access to all available GPUs.
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
--gpus=all: Enables access to all available GPUs.
docker run -d --device /dev/kfd --device /dev/dri -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama:rocm
After running the container, you can interact with Ollama through its API, typically at http://localhost:11434
--device /dev/kfd --device /dev/dri: Enables access to AMD GPU devices.ollama/ollama:rocm: Specifies the Ollama Docker image with ROCm support.
To run AI/LLM model
docker exec -it ollama ollama run llama3
The Llama 3.1 release introduces six new open LLM models based on the Llama 3 architecture. They come in three sizes: 8B, 70B, and 405B parameters, each with base (pre-trained) and instruct-tuned versions
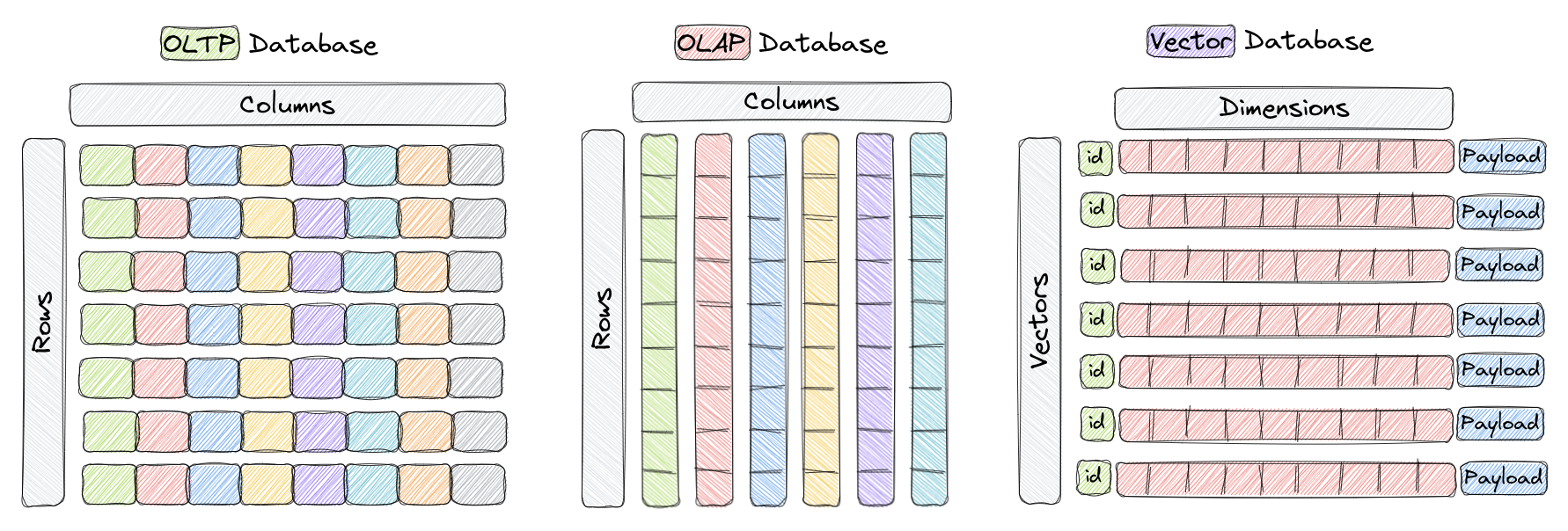
Qdrant “is a vector similarity search engine (DB) that provides a production-ready service with a convenient API to store, search, and manage points (i.e. vectors) with an additional payload.”
No comments:
Post a Comment