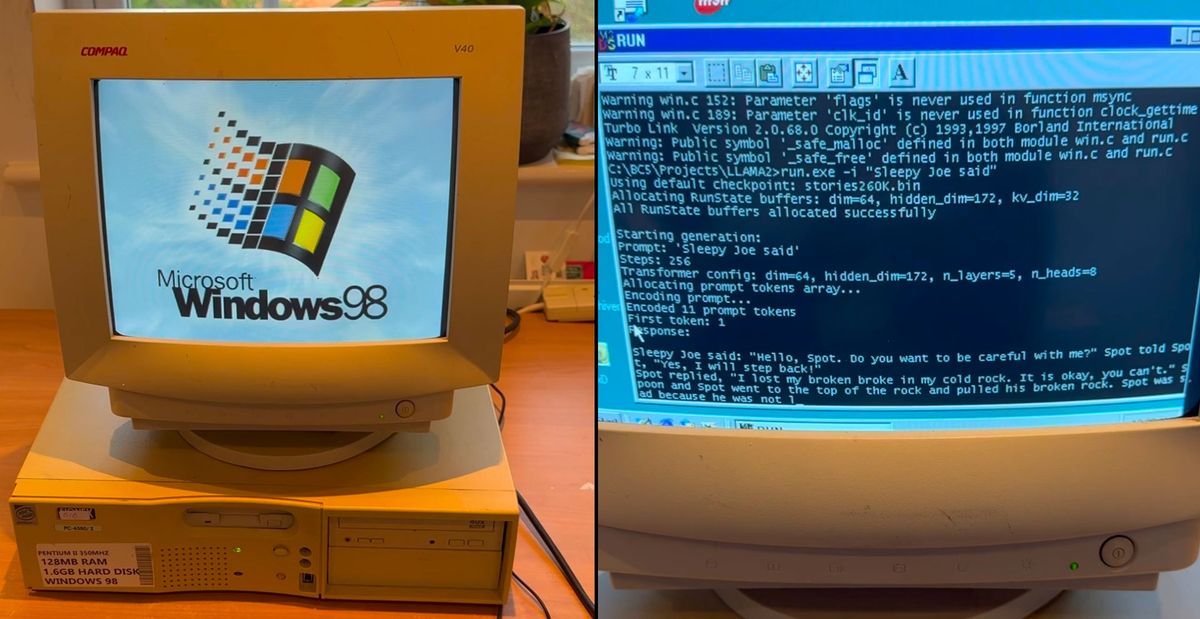
Pentium II with 128MB of RAM could generate an impressive 35.9 tok/sec.
Andrej Karpathy's llama2.c, which can be summarized as "700 lines of pure C that can run inference on models with Llama 2 architecture."
karpathy/llama2.c: Inference Llama 2 in one file of pure C @GitHub
by Andrej Karpathy