S3 Select and Glacier Select – Retrieving Subsets of Objects | AWS News Blog
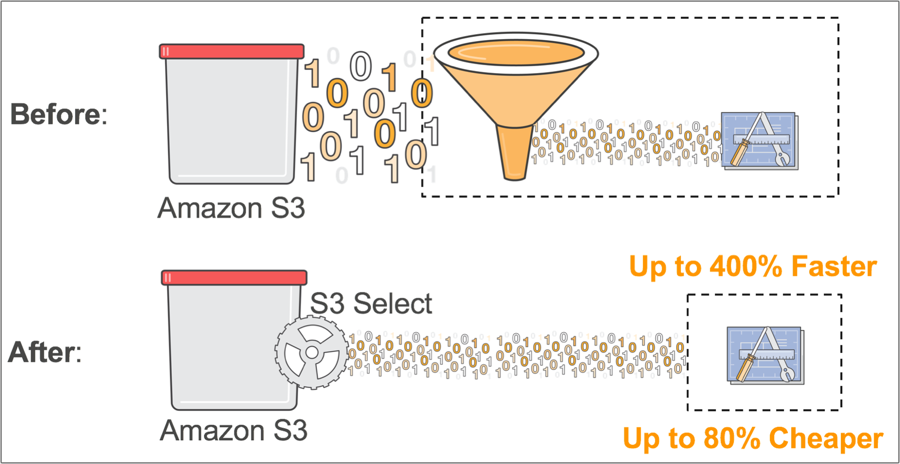
"With S3... individual objects can be as large as 5 terabytes. Data in object storage have traditionally been accessed as a whole entities, meaning when you ask for a 5 gigabyte object you get all 5 gigabytes. It’s the nature of object storage. Today we’re challenging that paradigm by announcing two new capabilities for S3 and Glacier that allow you to use simple SQL expressions to pull out only the bytes you need from those objects. This fundamentally enhances virtually every application that accesses objects in S3 or Glacier."
...
"As an (Python) example, let’s imagine you’re a developer at a large retailer and you need to analyze the weekly sales data from a single store, but the data for all 200 stores is saved in a new GZIP-ed CSV every day. Without S3 Select, you would need to download, decompress and process the entire CSV to get the data you needed. With S3 Select, you can use a simple SQL expression to return only the data from the store you’re interested in, instead of retrieving the entire object."
import boto3
s3 = boto3.client('s3')
r = s3.select_object_content(
Bucket='jbarr-us-west-2',
Key='sample-data/airportCodes.csv',
ExpressionType='SQL',
Expression="select * from s3object s where s.\"Country (Name)\" like '%United States%'",
InputSerialization = {'CSV': {"FileHeaderInfo": "Use"}},
OutputSerialization = {'CSV': {}},
)
...