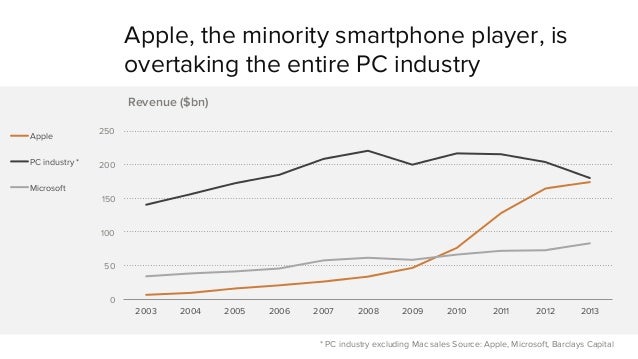
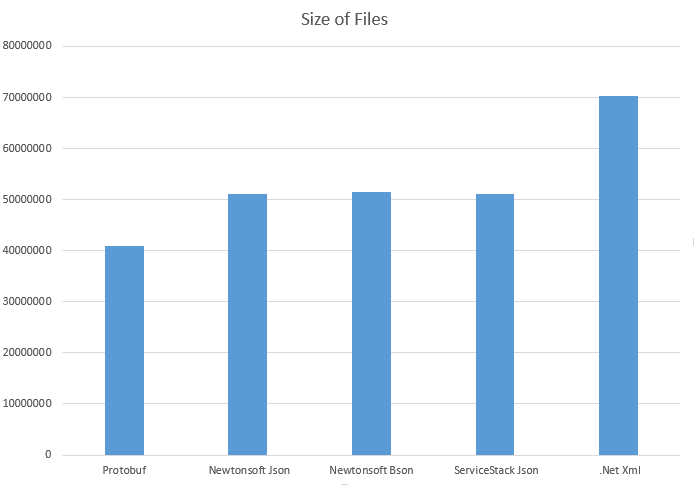
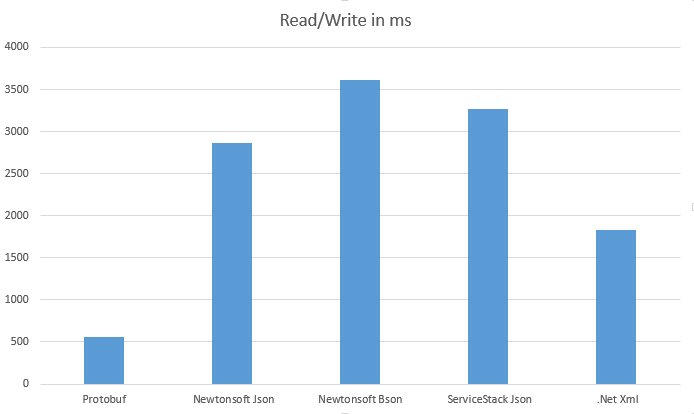
Google's Protocol Buffers data serialization is fast and creates compact files,
compared to text formats (XML, JSON) and some binary serializations.
One of reasons is that metadata are not saved, external schema is required, so it i not self-describing,
and a integer values are stored in compact way: smaller numbers take less space
This technique is called "
varint" and is very similar to UTF8 encoding for UNICODE characters,
in this case applied for integer numbers.
Encoding - Protocol Buffers — Google Developers
"Varints are a method of serializing integers using one or more bytes. Smaller numbers take a smaller number of bytes.
Each byte in a varint, except the last byte, has the most significant bit (msb) set – this indicates that there are further bytes to come. The lower 7 bits of each byte are used to store the two's complement representation of the number in groups of 7 bits, least significant group first."
1 (decimal) => 0000 0001 (encoded)
300 (decimal) => 1010 1100 0000 0010 (encoded)
has more bytes (1) first 7 data bits(010 1100) no more bytes(0) second 7 bits(000 0010)
000 0010 010 1100
→ 000 0010 ++ 010 1100
→ 100101100
→ 256 + 32 + 8 + 4 = 300
Another example of decoding; "msb" (most significant bit) indicates if there is more bytes
96 01 = 1001 0110 0000 0001
→ 000 0001 ++ 001 0110 (drop the msb and reverse the groups of 7 bits)
→ 1001 0110
→ 128 + 16 + 4 + 2 = 150
Obviously this encoding is good for some numbers and less good for others.
"150" would fit in one byte with all 8 bits ware used,
but in this case it takes 2 bytes since first (msb) bit is a "continuation" flag.
This technique is useful in particular for "key" part of key/value pairs,
since usually there is small number of fields for encoding.
UTF8 encoding has the same issue with multi-byte languages like Japanese,
where one character takes 3 x UTF8 bytes, or 1 x UTF16 word that is 2 bytes.
In that case it is 50% less effective to use UTF8.
On the other side, for English language UTF8 takes 1 byte,
and UTF16 takes 2 bytes, 100% increase.
Windows, .NET, Java, all use UTF16 in memory.