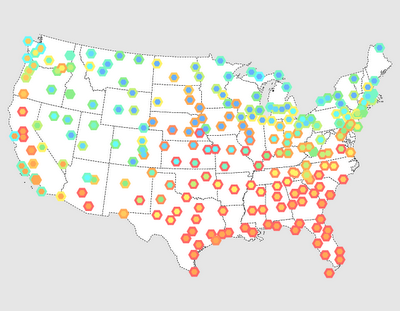
This is in particular visible with managed VM languages, like Java (48 Bytes for string "ABC" !!!)
With availability of large-memory computers, big data could fit in memory of a single machine...







 bad vs. good
bad vs. good 










{"person": {
"address": {
"city": "Anytown",
"postalCode": "98765-4321",
"state": "CA",
"street": "12345 Sixth Ave",
"type": "home"
},
"created": "2006-11-11T19:23",
"firstName": "Robert",
"lastName": "Smith",
"modified": "2006-12-31T23:59"
}}
["person",
{"created":"2006-11-11T19:23",
"modified":"2006-12-31T23:59"},
["firstName", "Robert"],
["lastName", "Smith"],
["address", {"type":"home"},
["street", "12345 Sixth Ave"],
["city", "Anytown"],
["state", "CA"],
["postalCode", "98765-4321"]
]
]




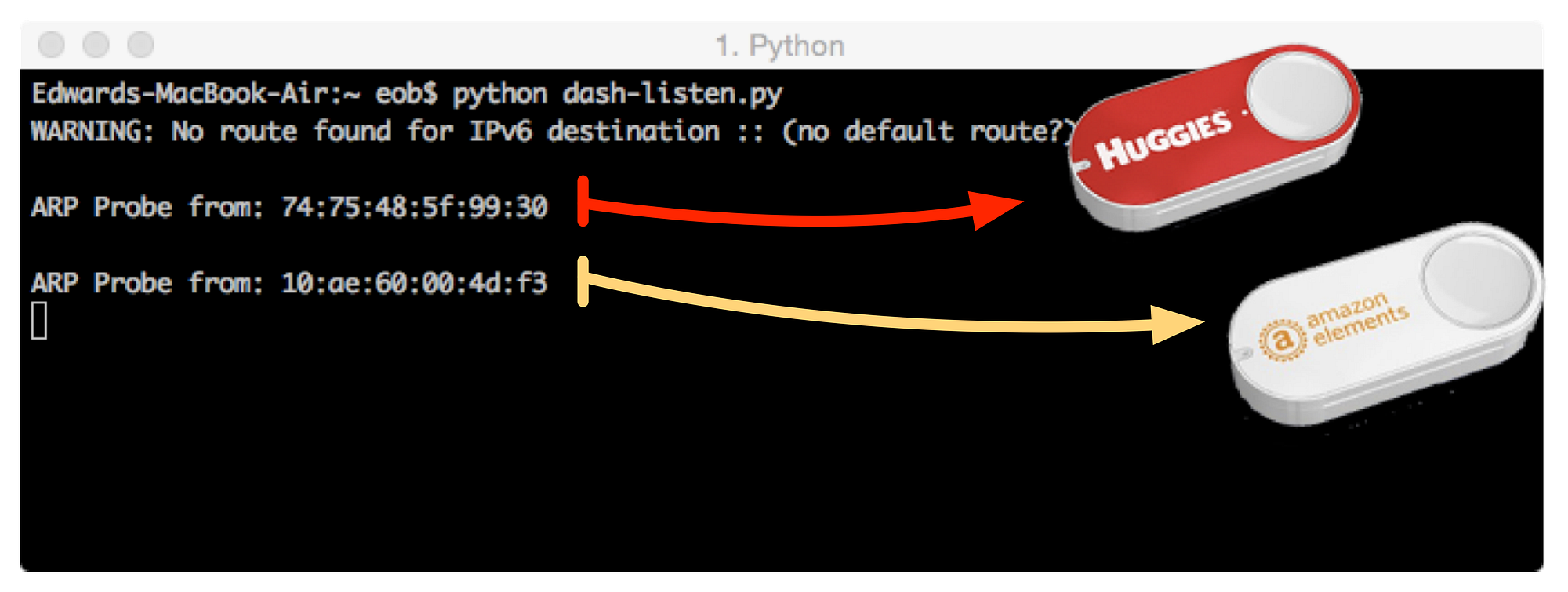
Lack of #DataScientists poses @SKA_telescope problem:http://www.itweb.co.za/mobilesite/index.php?option=com_content&view=article&id=145278 … #BigData #Astronomy#DataScience (see also @LSST)
This entry (chosen pretty much at random) has the following characteristics:
@user-references (@SKA_telescope)
#topical-references (#BigData)
shortened links (http://goo.gl/YrvpMd)
Account originator (@KirkDBorne)
Message identifier (not shown, but every twitter message has one, typically a GUID: f9732f07-ab02-46d4-b869-215e36576dc5, which I'll shorten to f9732f07)
A time stamp (not shown)
Retweet-reference (not shown, but typically an internal link to a previous tweet).
Additional human text message.





















