Wikidata (= Wikipedia data) are represented in "RDF" (Resource Description Framework)
format based on "triples": "Resource", "Property", "Value".
Originally RDF model is created for WWW,
to enable "Semantic Web" for representing data for web.
While RDF is not as widely used and popular as HTML,
it plays a very important role on web, i.e. in Google search results.
The Relationship Between Semantic Search and Google | BrightEdge
In fact this was an original meaning of Web 3.0 before Crypto adopted Web3 branding.
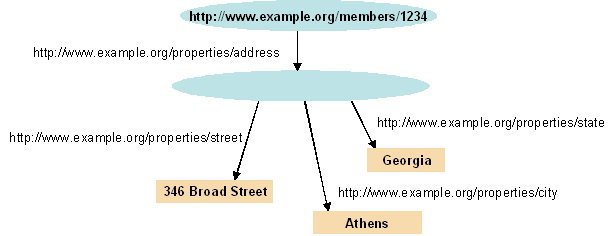
Any object stored in Wikidata (and Wikipedia) is a "resource",
and has a unique identifier, a number starting with "Q",
i.e. movie (film) "Forrest Gump" https://www.wikidata.org/wiki/Q134773
All properties of resources in Wikidata have unique identifier, a number starting with "P",
i.e. "title" https://www.wikidata.org/wiki/Property:P1476
For example, an RDF expression defining title of movie would be:
Please observe the final dot, ending the expression.
That is completing an RDF sentence, like in English: subject predicate object .
A property could be a simple value (a string, date, number), like "title" above,
or it can also be a reference to another resource,
i.e. "cast member" https://www.wikidata.org/wiki/Property:P161
For example, "resource" representing "Tom Hanks" is https://www.wikidata.org/wiki/Q2263
A RDF expression describing that "Tom Hanks" is a "cast member" of "Forrest Gump" movie:
This method of describing resources with "triples"
enables having multiple properties of the same type,
i.e. a movie can have many "cast members".
This is a major difference from a typical "relational database model"
On one side significantly simplify data modeling.
On other it requires handling every property value potentially an array.
For example, when RDF data are mapped into in-memory objects
the value of property would need to be defined as an array,
bot for simple value as well as references to other resources / objects.
Here is an example SQPARL query to get all properties of resource
where {
wd:Q134773 ?pt ?v.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
?p wikibase:directClaim ?pt .
}
and the query is effectively "pattern matching" for RDF triples.
Besides of Q and P identifiers, there is also concept of RDF "namespaces"
that helps identify specific interpretation for identifiers.
In this case prefix "wd:" means "wikidata resource" (id starting with Q)
and prefix "wdt:" means "wikidata property" (id starting with P)
short string names of resources and properties, in this case ?ptLabel and ?vLabel.
Another wikidata query syntax requirement to present label for property
is last line of the query, with "wikibase:directClaim".
In all, this is quite simple query that can describe any resource in wikidata!
If this is to be expressed in SQL it would be be a query vaguely like this
all wikidata resources are "global" and can have any number or properties,
and each property can have multiple values, simple types and reference (id) values.
In all, RDF and SPARQL are very generic and expressive,
and that requires different syntax than relational database and SQL.
Attributes of references between resources.
The RDF triples effectively describe a "property graph"
with "nodes", "properties" and "edges".
Graph "node" is a "resource" and an "edge" is a "reference" to another "resource" via "property" type.
As in previous example, resource "Forrest Gump" movie
has property "cast member" leading to resource "Tom Hanks". Simple.
But what is we need to add some properties (attributes) to such reference,
i.e. to describe "character name" played by "cast member?"
In the example above Tom Hanks plays character "Forrest Gump" in the movie with same name.
Technically the reference from one resource to another (via property)
can also be represented with an internal identifier, and that refence can have properties of its own.
Those properties of references are called "Qualifiers" in Wikidata,
and there is a specific syntax for expressing such queries.
Here is an example getting actors in a movies with names of characters played.
WHERE {
wd:Q134773 p:P161 ?s .
?s ps:P161 ?castMember .
?s pq:P453 ?character .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
Wikidata Query Service
Again, this is SPARQL syntax, and namespaces / prefixes "ps:" and "pq" are pre-defined by Wikidata and required in this case. The results includes all "cast members" with names (labels),
and with names of characters played in movie.
But is requires that the character name is defined, and not all cast members have this.
To get all cast members, including those without character assigned,
the SPARQL provides "OPTIONAL" syntax. The result is much longer list of values.
| wd:Q1357803 | Michael Conner Humphreys | wds:Q134773-f9760b4e-4f5e-7f16-ab68-0209ac07e512 | young Forrest Gump | wd:Q3077690 | Forrest Gump |
In this case the value is "wd:Q1357803" leaning to actor "Michael Conner Humphreys"
That comes as value of ?castMemberLabel" variable in the select statement.
That is an UUID/GUID, a "global/universal unique identifier". with prefix "wds:"
This means that each reference to another resource has own identifier!
that can be "simple type" (string), or a reference to another resource.
Too many references, but that is the nature of the data in general!
From query we see that this "qualifier" type property is P4633, and is optional.
They are optional, too, and represent a link to an "resource" created for describing the character in the movie. In this case the values are wd:Q3077690 and Forrest Gump.
Why is this separate resource useful?
Because with this we can have multiple references and additional info for describing the character.
A few lines below is the record representing Tom Hanks in the same role, just playing adult Forest Gump.
| wd:Q2263 | Tom Hanks | wds:q134773-98BA2138-A987-4793-9F4E-4D44AC0FD4D8 | Forrest Gump | wd:Q3077690 | Forrest Gump |
This example also helps illustrate value of using unique identifiers rather than just strings,
since in this case we have "Forrest Gump" as label / title of the movie (in English),
then same value as name of the character / role played by multiple actors.
With provided identifiers it is clear in what context is each one used,
and each of the items can be described without any limitations!
This is much more powerful data model than typical object oriented or relational data model!
It is essentially a "property graph" data model.
And yet, it can be represented as objects in memory, as well as data in SQL database!
And it can also represent any object model, as well as any relational database.
SPARQL/WIKIDATA Qualifiers, References and Ranks - Wikibooks, open books for an open world
Wikidata:SPARQL query service/queries/examples - Wikidata
Wikidata Query Service/User Manual - MediaWiki
database - wikidata get all properties with labels and values of an item - Stack Overflow
Wikidata Query Service: example query!
Wikidata Query Service example with more details, including id's
Wikidata Query Service optimized query, app props with qualifiers
SELECT ?p ?p_Label ?v_ ?v_Label ?a ?aLabel ?e_ ?e_Label {
VALUES ?q { wd:Q134773 }
?q ?p ?s . # "statement property"
?s ?ps ?v_ . # "statement value / reference"
?p_ wikibase:claim ?p.
?p_ wikibase:statementProperty ?ps. # ?ps == ?p
OPTIONAL {
?a wikibase:qualifier ?e . # "qualifier property"
?s ?e ?e_ . # "qualifier value / reference"
}
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" }
} ORDER BY ?p ?v_ ?a ?e_
No comments:
Post a Comment