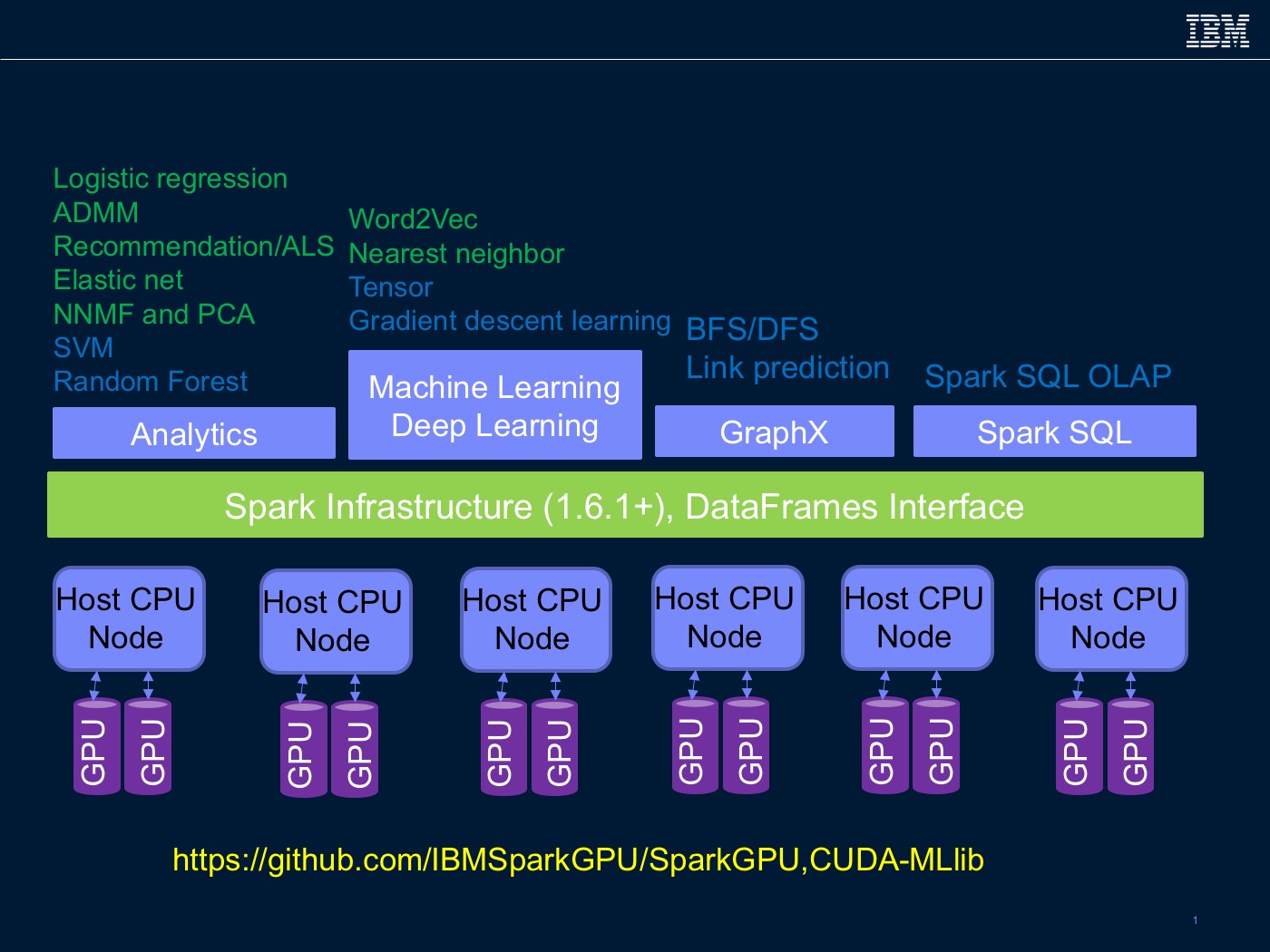
"Spark has emerged as the infrastructure of choice for developing in-memory distributed analytics workloads. It provides high-level abstractions in multiple languages (e.g., Java, Scala, and Python) that hide the underlying data and work distribution operations such as data transfer to and from the Hadoop Distributed File System (HDFS) or that maintain resiliency in the presence of system failures. Spark also provides libraries for relational Online Analytical Processing (OLAP) using SQL, machine learning, graph analytics, and streaming workloads."
Spark is also part of Microsoft Azure HDInsight.
No comments:
Post a Comment